I had been cynical toward AI for more than a decade since late undergraduate years, long before LLM became popular. There were many factors that shaped my attitude (both my experience with some researchers who just use AI as a buzzword and the overly hyped media coverage), but I have to admit: most of the time I wasn’t even an active user with enough first-hand experience to draw a conclusion, and during the few years I actually worked on it I saw decent results (but that’s prior to LLM and for more traditional classification problems).
2025 was when I became a regular user of AI, more specifically LLM, and it provided me impressive results times and again and I got a better understanding of its limitations in more concrete terms.
At work
I only started to use Cursor this April (though I fabricated my memory to push it back to November 2024, Cursor debunked it with the year-end summary).
At first I only used it to write tests. Where I work, most of the code are reading from and writing to DB directly (I’ll rant about it for another time), and for “unit tests”, you have to start a in memory DB instance, create a whole bunch of records (literally with Model.create()), then apply some business logic, and finally make assertions on DB records (again with Model.find()). Cursor instantly freed me from this tedious job, and most of the times created the right set of tests with the combination of conditions you gave it.
Encouraged by this early experience, I began to give it more complicated tasks with more vague and high-level prompts. It generated reasonable code most of the times, occasionally with repetitive code where you needed to ask it to improve re-usability. And it definitely boosted my productivity.
Open question: when LLMs reliably write the “right” code, does it mean you have too much similar patterns throughout your code base, and you need a better abstraction layer? And theoretically, can you reduce (conceptual) repetition to the point LLMs no longer work?
Other than writing code, my other experiences with LLMs were more underwhelming, especially with agents where I gave up at the setting up step several times. And I still believe it’s more useful to provide an API to let users programmatically query data and make changes than the natural language interface. And APIs feel second-class citizens compared to apps / websites for most if not all products, if they exist at all.
For side projects
I tried to use Gemini to help me parse the board for NYT pips. The results weren’t so impressive: it barely worked for easy, and never came close to medium not to mention hard. Even for easy, it would give wrong results more often than not, and give different results for the same board every time you call it. This sort of matched what I had read that LLM struggled to count letters.
Two concrete examples from Dec 30, 2025:
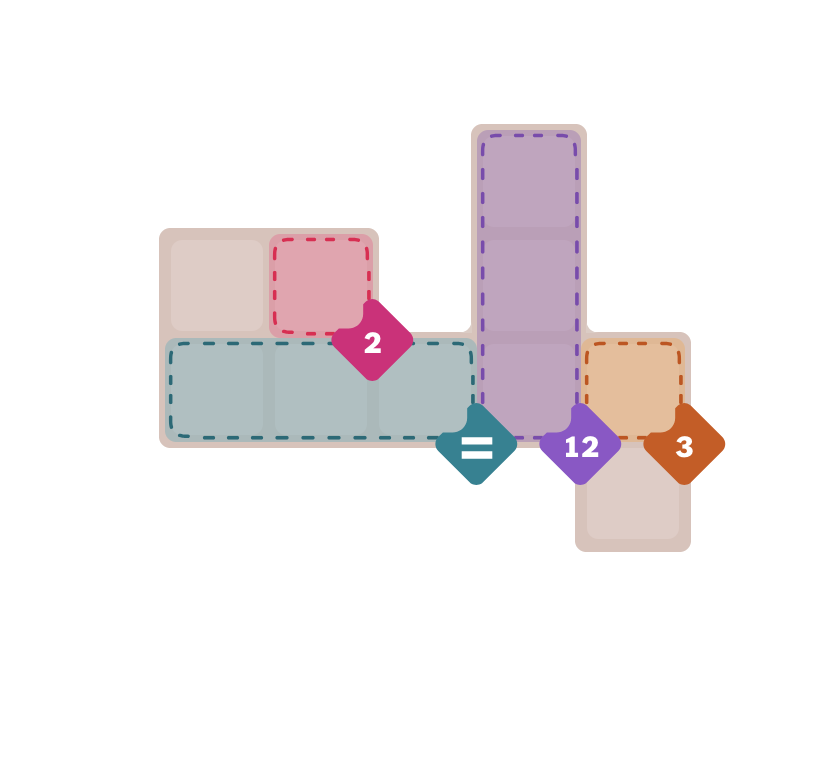
The generated JSON is here: https://gist.github.com/boyou/fad9e07cad832e860b64efcf35bb9b3a.
- Even the number of rows and columns are wrong.
- It doesn’t use
{"x": 0, "y": 1}, but uses nested integer array. - None of the regions are correct.
- This is definitely one of the worst results I got, even worse than the medium below, while the example from my previous post was almost right.
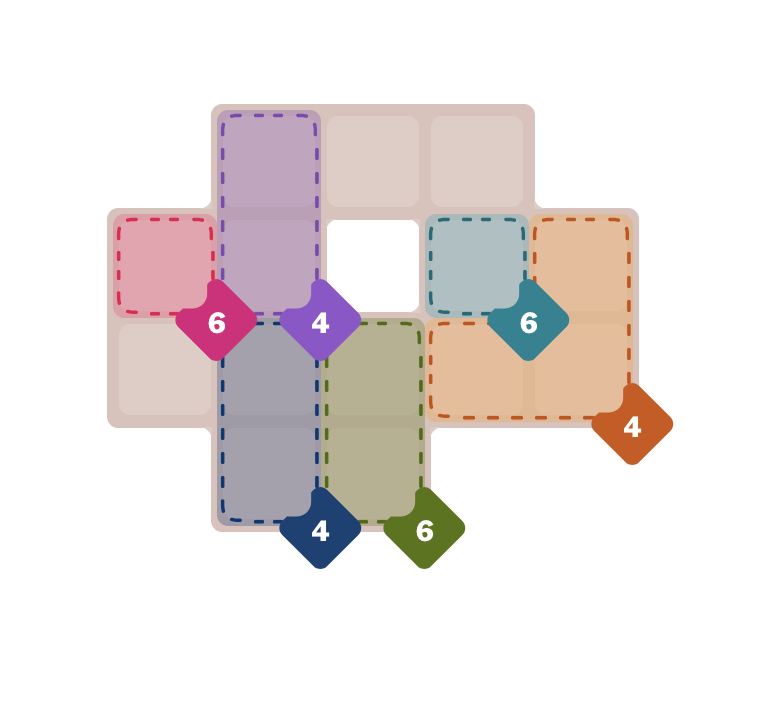
The generated JSON is here: https://gist.github.com/boyou/be8ec6b87ddb9b2dfcbe1a75d6857699.
- It somehow got more things right: the number of rows and columns, the format.
- It got some regions right (like the purple 4 and the blue 4), but with many more incorrect.
- It still missed many of the empty white cells.
IMO this will restrict the scenarios under which these models can be used (where variation is acceptable or even desirable like image generation, precision is not a requirement, and you have a large margin for errors), and I’m wondering how many of the shared demos online are cherry picked or over-fitted.
Other stuff
There are also a couple of one time code I let Gemini generate for me.
I have some Korean MP3s from TTMIK vocabulary class, where each sentence is read 4 times, and I’d like to take just the first 2 times. A while ago I thought this might require some signal processing, but Gemini just used intervals of low decibel as sentence boundaries.
I also want to have a quick animation of how air is circulating in a room, Gemini wrote some legitimately looking code with convincing comments, but the result doesn’t look like air simulation at all. (I turned to Blender in the end.)
So you still need some domain knowledge, or at least a reliable way to verify the result, instead of just trusting their output.
So what do I think about AI and “the next big thing” now
At least in the realm of software engineering, I might be in the late majority group for adopting LLM (luckily not “laggards”).
I’ll try to shift to “early adopters” or “early majority”, to use new technology wherever applicable and get a more accurate sense of its pros and cons. The last thing I’ll do is to be cynical and deny it as a “hype” altogether.